
On November 18, 2025, Cloudflare—a company that powers and protects approximately 20% of the internet—experienced a significant global outage. This disruption rippled across the digital landscape, taking down major platforms including X (formerly Twitter), ChatGPT, Shopify, and thousands of other websites and services worldwide. As businesses increasingly rely on cloud infrastructure, understanding this outage provides valuable insights into internet reliability and the hidden dependencies that keep our digital world functioning.
What Is Cloudflare and Why Is It Critical to the Internet?
Cloudflare operates as a content delivery network (CDN) and distributed denial-of-service (DDoS) mitigation service. Founded in 2009, the company has grown to become a critical component of internet infrastructure, handling traffic for approximately one-fifth of all websites globally. When you visit a Cloudflare-protected website, your connection doesn’t go directly to that site—instead, it routes through Cloudflare’s servers first.
This intermediary position allows Cloudflare to provide several essential services. It defends websites against malicious attacks, accelerates content delivery by caching data closer to users, and optimizes traffic routing for improved performance. Major corporations, small businesses, and even government agencies rely on Cloudflare’s services to keep their digital operations secure and efficient.
As cybersecurity expert Mike Chapple explained: “When you access a website protected by Cloudflare, your computer connects to the nearest Cloudflare server, which might be very close to your home. That protects the website from a flood of traffic and provides you with a faster response. It’s a win-win for everyone—until it fails, and 20% of the internet goes down simultaneously.”
Timeline of the 2025 Cloudflare Outage
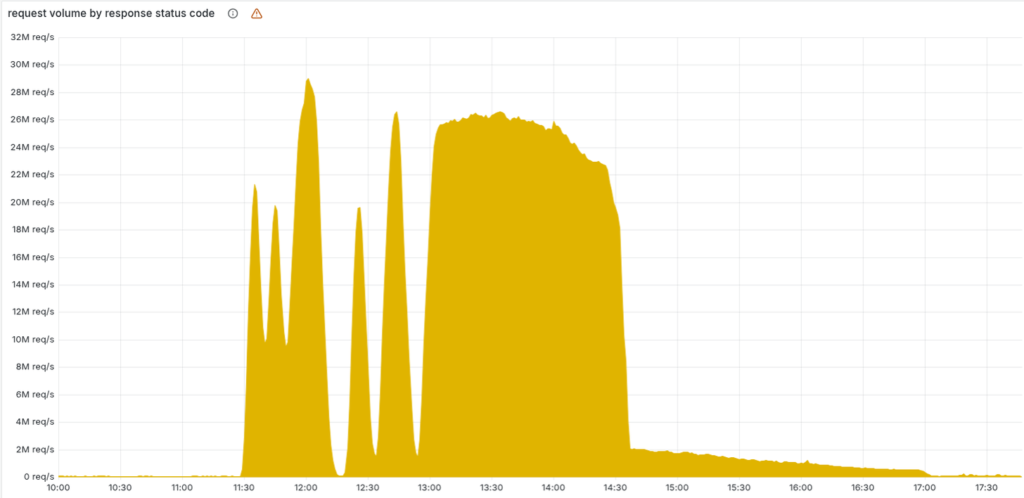
| Time (ET) | Event | Impact |
| 5:20 AM | Cloudflare observes “spike in unusual traffic” | Initial service degradation begins |
| 6:30 AM | Major outage officially begins | Widespread service disruptions reported globally |
| 7:48 AM | Cloudflare acknowledges issue on status page | Company confirms “internal service degradation” |
| 8:30 AM | Engineers identify root cause | Work begins on implementing fix |
| 9:57 AM | Fix implemented | Services begin to recover |
| 12:44 PM | Full service restoration | All systems return to normal operation |
The outage lasted approximately 6 hours from initial detection to full resolution. During this period, Cloudflare’s engineering teams worked to identify the root cause and implement a solution. The company provided regular updates through its status page, though many users first learned of the issue through error messages on websites they were attempting to access.
Root Cause Analysis: What Triggered the Outage
According to Cloudflare’s official statement, the root cause of the outage was an automatically generated configuration file used to manage threat traffic. This file “grew beyond an expected size of entries,” which triggered a crash in the software system responsible for handling traffic across several Cloudflare services.
Cloudflare CTO Dane Knecht provided additional technical details, explaining that “a latent bug in a service underpinning our bot mitigation capability started to crash after a routine configuration change we made.” This cascaded into a broader degradation of Cloudflare’s network and other services.
The company emphasized that there was no evidence the outage resulted from an attack or malicious activity. Rather, it was a technical failure stemming from their internal systems. The issue began when Cloudflare observed a “spike in unusual traffic” around 5:20 AM ET, which eventually triggered the configuration file problem.
“Given the importance of Cloudflare’s services, any outage is unacceptable. We apologize to our customers and the internet in general for letting you down today.”
Impact Assessment: Services and Regions Affected
Major Platforms Affected
- X (formerly Twitter)
- OpenAI’s ChatGPT
- Anthropic’s Claude AI
- Shopify e-commerce platform
- Perplexity AI
- Truth Social
- Spotify
- PayPal
- Canva
- League of Legends
- Genshin Impact
- NJ Transit digital services
Impact by Sector
The outage demonstrated the widespread dependency on Cloudflare across various sectors. AI services were particularly affected, with major platforms like ChatGPT, Claude, and Perplexity experiencing downtime. Social media platforms, e-commerce sites, financial services, and even transportation systems reported disruptions.
The geographic impact was truly global, with users from North America, Europe, Asia, and Australia all reporting issues. This highlights the interconnected nature of today’s internet infrastructure—when a major provider like Cloudflare experiences problems, the effects are felt worldwide regardless of physical location.
For many businesses, the outage resulted in lost revenue, particularly for e-commerce platforms that rely on continuous availability. While the exact financial impact hasn’t been quantified, Cloudflare’s own shares dropped more than 2% following the incident, indicating market concern about the reliability of their services.
Cloudflare’s Response and Communication
Throughout the outage, Cloudflare maintained communication through multiple channels. The company’s primary method of updating users was through its status page, where it acknowledged the issue at 7:48 AM ET, describing it as an “internal service degradation” that was causing intermittent impacts to services.
Cloudflare CTO Dane Knecht also provided updates via social media, offering technical insights into the problem and the steps being taken to resolve it. In a post on X, he stated: “I won’t mince words: earlier today we failed our customers and the broader Internet when a problem in Cloudflare network impacted large amounts of traffic that rely on us. The sites, businesses, and organizations that rely on Cloudflare depend on us being available and I apologize for the impact that we caused.”
The company’s transparency about the issue was generally well-received, though some users criticized the initial delay in acknowledging the problem. Cloudflare continued to provide updates even after implementing the fix, noting that they were “continuing to monitor for errors to ensure all services are back to normal.”
Technical Details: The Fix and Recovery Process
Resolving the outage required Cloudflare’s engineering teams to address the underlying issue with the configuration file that had grown beyond its expected size. The company implemented several technical measures to restore service:
- Identified the specific configuration file causing the crash in their bot mitigation system
- Implemented size limitations and validation checks to prevent similar occurrences
- Deployed changes to restore dashboard services first
- Gradually restored broader application services
- Temporarily disabled their encryption service called Warp in London during the recovery process
- Implemented continuous monitoring to ensure all services returned to normal operation
The recovery process was methodical, prioritizing critical services first. Even after implementing the primary fix, Cloudflare noted that “some Cloudflare services will be briefly degraded as traffic naturally spikes post-incident,” indicating the complex nature of restoring services at their scale.
The technical complexity of the issue highlights the challenges of maintaining large-scale internet infrastructure. Even routine configuration changes can trigger unexpected behaviors in complex systems, particularly when those systems are responsible for handling significant portions of global internet traffic.
Comparison with Previous Cloudflare Outages
The 2025 outage wasn’t Cloudflare’s first significant service disruption. In June 2022, the company experienced an outage affecting 19 of its data centers, causing approximately 90 minutes of disruption to major websites and services globally. Earlier, in 2019, a software bug led to another notable outage.
Comparing these incidents reveals some patterns in Cloudflare’s infrastructure challenges:
| Year | Duration | Cause | Scale of Impact |
| 2019 | ~30 minutes | Software bug in deployment | Moderate – affected specific regions |
| 2022 | ~90 minutes | Issue affecting 19 data centers | Significant – global impact |
| 2025 | ~6 hours | Configuration file size issue | Severe – widespread global disruption |
The 2025 outage stands out as particularly significant in both duration and impact. While previous incidents were resolved relatively quickly, the November 2025 outage lasted approximately six hours, making it one of Cloudflare’s most prolonged service disruptions to date. This suggests increasing complexity in Cloudflare’s systems as the company continues to grow and support more of the internet’s infrastructure.
Lessons Learned and Future Prevention
Following the outage, Cloudflare announced several measures to prevent similar incidents in the future:
Technical Improvements
- Enhanced validation for configuration file sizes and content
- Improved testing protocols for configuration changes
- Additional redundancy in critical systems
- Better isolation between services to prevent cascading failures
- Expanded monitoring capabilities to detect unusual traffic patterns earlier
Operational Changes
- Revised incident response procedures
- More frequent testing of failover systems
- Enhanced communication protocols during outages
- Additional training for engineering teams
- Regular audits of critical infrastructure components
The incident highlighted broader lessons for the entire internet infrastructure industry. As Alan Woodward, professor of cybersecurity at the University of Surrey, noted: “This incident, as with the recent outage at AWS, shows how reliant some very important internet-based services are on a relatively few major players. It’s a double-edged sword as these service providers need to be large to provide the scale and global reach required by big brands. But when they fail, the impact can be significant.”
This concentration of internet infrastructure among a few key providers creates inherent vulnerabilities. When companies like Cloudflare, Amazon Web Services, or Microsoft Azure experience problems, the effects ripple across the entire digital ecosystem. This has prompted discussions about the need for greater diversity in internet infrastructure and improved resilience strategies.
Industry Reactions and Expert Commentary
The 2025 Cloudflare outage sparked significant discussion among technology experts and industry leaders about internet reliability and infrastructure dependencies.
“We’re seeing outages happen more frequently, and they’re taking longer to fix. That’s a symptom of strained infrastructure: increased AI load, streaming demand, and ageing capacity all pushing systems past the edge.”
Niusha Shafiabady, a computational intelligence expert from Australian Catholic University, called the incident “a wakeup call,” adding: “We need transparency, backup routes and multi-provider set-ups so one company’s glitch can’t darken the whole web.”
The outage also raised questions about the increasing concentration of internet infrastructure. Coming just weeks after significant disruptions at Amazon Web Services and Microsoft Azure, the Cloudflare incident highlighted growing concerns about the internet’s resilience. Some experts suggested that the increasing adoption of AI services, which require substantial computing resources, may be putting additional strain on existing infrastructure.
Business leaders expressed concern about the economic impact of such outages. For e-commerce platforms like Shopify, even a few hours of downtime can result in significant revenue losses. This has prompted many organizations to reconsider their dependency on single providers and explore multi-cloud strategies that could provide greater resilience against future outages.
Conclusion: The Fragility of Our Digital Infrastructure
The November 2025 Cloudflare outage serves as a powerful reminder of the hidden dependencies that underpin our digital world. As businesses and individuals increasingly rely on cloud services, the impact of infrastructure failures becomes more pronounced. What began as a technical issue with a configuration file cascaded into a global disruption affecting millions of users across countless services.
This incident highlights both the remarkable resilience and inherent fragility of the internet. While the web was designed to route around damage, the concentration of critical services among a handful of providers creates new vulnerabilities. As we continue to build more complex digital systems and migrate more essential services online, addressing these structural challenges becomes increasingly important.
For businesses and organizations, the Cloudflare outage underscores the importance of robust continuity planning and diversified infrastructure strategies. For infrastructure providers like Cloudflare, it emphasizes the critical responsibility they bear in maintaining the digital foundations upon which so much of modern society now depends.

Comments are closed.